
EN
在信創(chuàng)背景下,金融機構(gòu)系統(tǒng)遷移面臨一個現(xiàn)實,底層硬件體系多樣化,例如C86+DCU、ARM+昇騰等。如果上層應用軟件(如核心業(yè)務系統(tǒng)中的OCR識別引擎)每次適配一種新硬件,就需要開發(fā)和維護一個獨立的軟件版本。
這會直接導致以下問題:
●開發(fā)成本激增: 每適配一種硬件組合,都意味著一次獨立的開發(fā)、測試和部署流程。
●運維成本失控: 運維團隊需要同時維護多個軟件版本,版本管理混亂,排查問題異常困難,人力成本和系統(tǒng)風險上升。
●投資無法延續(xù): 當?shù)讓佑布俅紊墦Q代時,之前的軟件投資很可能作廢,需要推倒重來,造成資源浪費。
一個原生適配、統(tǒng)一架構(gòu)的平臺是解決上述問題的關(guān)鍵。例如易道博識的智能文檔處理平臺(簡稱DeepIDP),它的核心價值在于,從軟件底層就完成了對所有主流國產(chǎn)化硬件的適配。
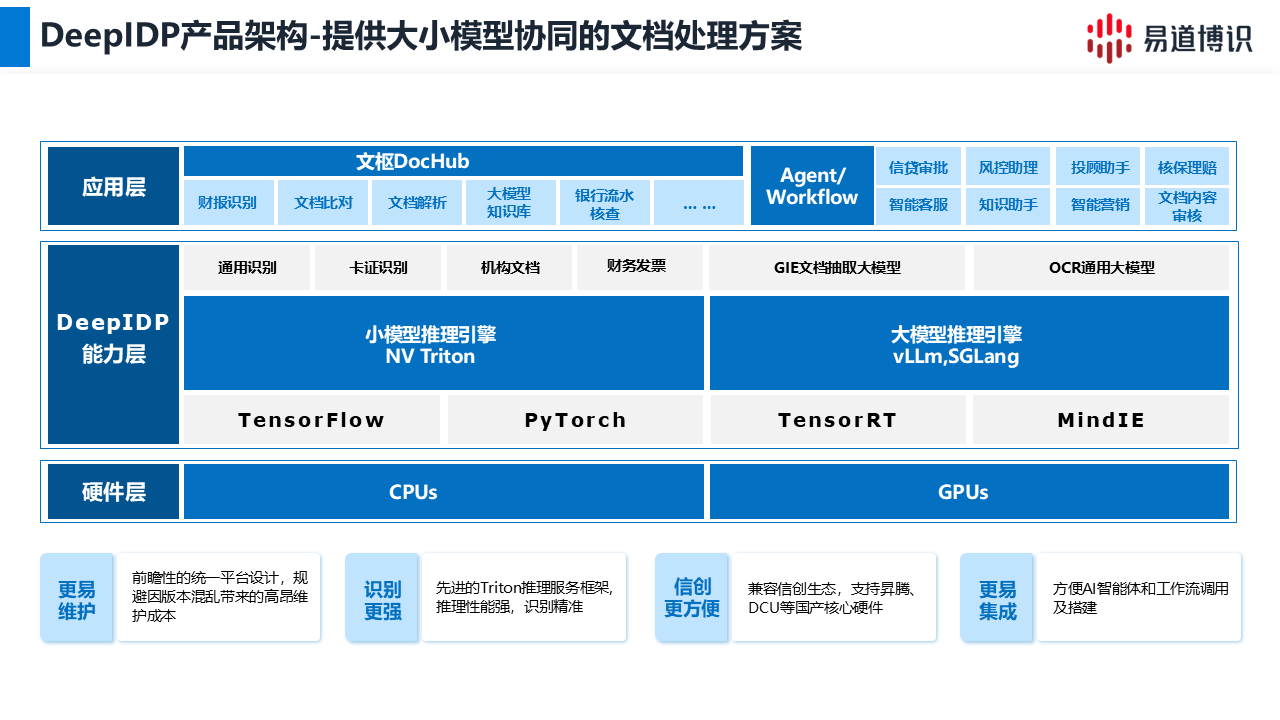
1. 如何降低維護成本?
僅需一套軟件版本: 運維團隊只需要面對一個統(tǒng)一的軟件架構(gòu)。無論底層是哪種國產(chǎn)芯片或服務器,上層的AI能力和應用都是一致的,告別版本混亂。例如, 某銀行的核心系統(tǒng)同時在ARM和C86兩種架構(gòu)的服務器上運行。通過統(tǒng)一平臺,他們部署的是同一套DeepIDP軟件,開發(fā)和運維團隊無需再為不同架構(gòu)維護兩套代碼,人力成本降低了至少50%。
2. 如何保障投資的連續(xù)性?
平滑遷移: 統(tǒng)一架構(gòu)確保了AI能力的投資是可延續(xù)、可擴展的。未來即使信創(chuàng)硬件再次迭代,上層的智能應用也無需重構(gòu),可以平滑遷移,保護了前期的IT投資。
金融業(yè)務涉及的文檔類型極其復雜,從版式固定的身份證、發(fā)票,到版式千變?nèi)f化的業(yè)務申請單、對賬單。單一模型難以勝任所有場景。
一個常見的誤區(qū)是認為一個強大的大模型就能解決所有問題。 實際上,最高效的策略是“大小模型協(xié)同”。

●專用小模型:處理高頻、標準文檔
任務: 識別身份證、銀行卡、發(fā)票、車票等版式固定的文檔。
優(yōu)勢: 速度極快、精度極高、資源占用小,最適合處理業(yè)務流程中出現(xiàn)頻率最高的標準化單據(jù)。
●大模型:處理非標、長尾文檔
任務: 識別各類申請單、合同、對賬單、醫(yī)療單據(jù)等版式不固定、字段靈活的復雜文檔。
優(yōu)勢:
■靈活抽取: 僅需通過提示詞(Prompt)告知模型需要抽取的字段(如“抽取合同中的甲方和簽約日期”),即可從任意版式中提取信息。
■金融領(lǐng)域優(yōu)化: 經(jīng)過金融行業(yè)數(shù)據(jù)二次訓練的大模型,能更精準地理解復雜表格和上下文,抽取精度更高。
■數(shù)據(jù)可溯源: 這是保障業(yè)務可信度的關(guān)鍵。平臺能將抽取的每一個字段(如JSON結(jié)果中的一個數(shù)值)精確關(guān)聯(lián)回原始影像的具體坐標位置,方便人工核驗和審計。
僅僅提取出數(shù)據(jù)是不夠的,核心是要讓AI能力融入業(yè)務,實現(xiàn)端到端的自動化。
1. 如何讓AI智能體(Agent)按需調(diào)用? 易道博識智能文檔處理平臺提供一系列“AI原子能力”(如文檔分割、分類、各類識別模型等),讓智能體可以像調(diào)用工具一樣靈活使用。
例如:財務報銷審核Agent
○分割與分類: Agent首先調(diào)用“圖像分割”與“文檔分類”能力,將一疊報銷單據(jù)自動拆分,并識別出哪些是發(fā)票,哪些是報銷申請單。
○分發(fā)與抽取: 接著,Agent將發(fā)票分發(fā)給“小模型”快速提取金額、日期;將報銷申請單分發(fā)給“大模型”抽取報銷事由、部門等信息。
○推理與決策: 最后,Agent利用大模型的推理能力,結(jié)合企業(yè)財務規(guī)則(如報銷金額是否超標),自動輸出“審核通過”或“駁回”的結(jié)論。

問題1:這套OCR識別系統(tǒng)支持哪些具體的國產(chǎn)硬件和操作系統(tǒng)?
回答: 易道博識智能文檔處理平臺從底層架構(gòu)原生適配主流國產(chǎn)化硬件,全面兼容C86+DCU、ARM+昇騰等多種信創(chuàng)體系,并支持麒麟、統(tǒng)信等國產(chǎn)操作系統(tǒng)。其核心優(yōu)勢在于,無論底層硬件如何組合,提供給上層應用的都是統(tǒng)一、穩(wěn)定的服務接口。
問題2:大模型處理金融行業(yè)復雜表格的精度如何?
回答: 精度主要通過兩方面保證:首先,智能文檔處理平臺選用的大模型是經(jīng)過海量金融行業(yè)特有文檔(如復雜對賬單、年報、招股書等)進行二次訓練和微調(diào)的,使其能更深刻地理解金融領(lǐng)域的上下文和版式。其次,其強大的溯源能力可以將每個抽取結(jié)果精準定位回原文,極大地方便了人工核驗,形成了一個“AI處理+人工校驗”的質(zhì)量閉環(huán)。





