
EN
專業的報表OCR識別錄入系統通過高精度識別、智能模板和自動邏輯校驗,將非結構化報表轉化為結構化數據,極大提升金融機構的數據處理效率與準確性。
對于銀行、證券、保險等金融機構而言,財報是評估企業信用、洞察投資價值的核心依據。然而,處理海量、格式各異的紙質或PDF財報,長期依賴耗時耗力的人工錄入與復核,已成為業務敏捷性與風險控制的關鍵瓶頸。本文將深度解析一款專業級財報OCR系統如何從技術內核到業務價值,全面升級金融機構的數據能力。
一個常見的誤區是認為任何OCR工具都能識別財報。事實上,兩者在目標和技術路徑上存在本質差異。
●目標維度: 通用OCR的目標是“讀文”,即盡可能準確地還原文本內容;而財報OCR的目標是“識數”并“理解結構”,它需要理解“資產負債表”是一個整體,并知道“流動資產”與“流動負債”之間存在勾稽關系。
●技術維度: 通用OCR模型訓練數據來源廣泛,對財報中緊湊的數字、缺失的表格線、特定的會計科目名稱識別效果不佳。專業系統則使用海量財務文檔進行專項訓練,對數字和表格的識別精度有數量級的提升。
●輸出維度: 通用OCR輸出的是無序的文本行或格子,仍需大量人工整理;專業財報OCR輸出的是按會計科目分類、可直接導入數據庫或分析軟件的結構化數據記錄。
該系統為解決財報處理難題,構建了一個層層遞進的技術閉環,經測試,在5分鐘內即可錄入原先需要2小時人工錄入的財報。
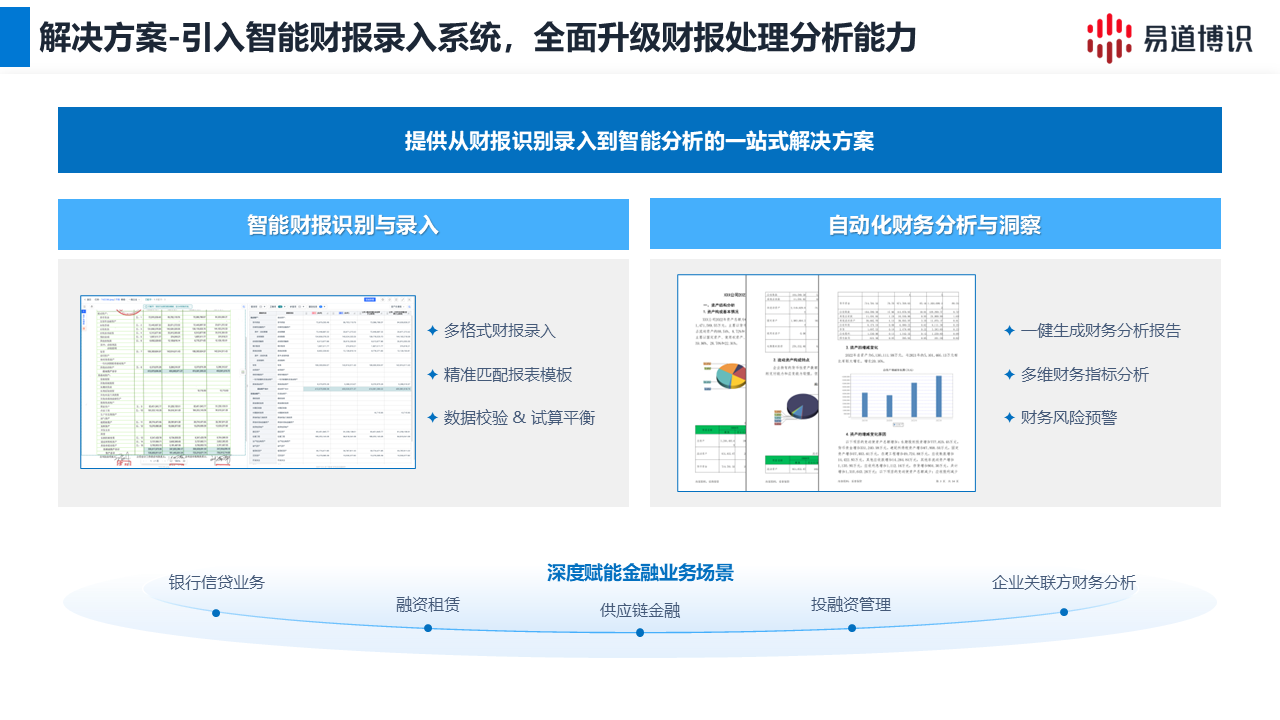
1.基礎層:高精度OCR識別引擎。 系統不僅采用先進的OCR核心,更關鍵的是針對金融文檔進行了全方位優化。其圖像預處理模塊能自動校正因掃描造成的傾斜、扭曲,并通過去噪、銳化提升圖像質量。隨后的版面分析模塊能精準定位表格區域,確保每一個數據單元格都被正確捕捕獲。
2.認知層:智能模板適配與科目識別。 系統超越了一般字符識別,具備了初步的“閱讀理解”能力。它預置了覆蓋主流會計準則的模板庫,并能智能關聯“營業收入”、“主營收入”等不同表述的同一科目。更重要的是其自學習能力,面對新報表格式,可通過少量樣本進行訓練,快速生成新模板,極大提升了系統的適應性和可持續性。
3.風控層:內置財務邏輯校驗機制。 經驗表明,超過20%的企業提交財報存在不同程度的勾稽關系錯誤。系統內嵌了豐富的校驗規則,可自動進行跨單元格、跨頁面的數據邏輯檢查,如檢查“資產=負債+所有者權益”是否平衡,并對不匹配、異常波動的數據點進行醒目標記與風險提示,為審計與風控人員提供了第一道高效防線。
4.價值層:自動化數據結構化與輸出。 系統的終極目標是將非結構化信息轉化為可計算的數據資產。它能夠將識別并校驗后的數據,按預設格式輸出為Excel、JSON等標準接口,并可與金融機構內部的信貸審批系統、風險管理平臺、商業智能系統進行無縫集成,打通了從文檔到決策的“最后一公里”,實現了端到端的自動化。

問題:財報OCR識別錄入系統與現有業務系統集成難度大嗎?
回答:系統提供標準API接口和多種數據輸出格式(如Excel, JSON),與常見的信貸、風控系統集成經驗成熟,技術難度可控,實施周期明確。
問題:財報OCR識別錄入如何保證長期的識別準確率?
回答:系統具備持續學習能力。通過用戶對識別結果的反饋和修正,模型可以進行迭代優化,從而在面對新字體、新格式時能自我進化,保持高準確率。





